Your customer database has 50,000 addresses. How many of them are duplicates?
If you're thinking "maybe a few hundred," you're probably off by a factor of ten. I've seen datasets where 15% of supposedly unique customer records were actually the same person living at the same location, just recorded differently across systems.
The culprit isn't bad data entry (well, not entirely). It's that addresses are deceptively complex. What looks like a simple string of text is actually a structured piece of information with dozens of acceptable variations, regional quirks, and formatting conventions that no two systems seem to agree on.

Why Addresses Are Deceptively Complex
Think about how you'd write your own address. Now think about how your grandmother might write it. Or how it appears on your driver's license versus how Amazon stores it. Same location. Probably five different formats.
The problem starts with what seems like a basic question: what even is an address? At minimum, you need enough information for a letter to find its way to a specific location. But "enough information" varies wildly depending on context, country, and whoever designed the form you're filling out.
A rural address in Wyoming might be a ranch name and a route number. A New York City apartment needs a building number, street, unit, and probably a buzz code. Neither format works for the other location, and both are valid addresses.
This fundamental ambiguity cascades through every system that touches address data. Your CRM stores addresses one way. Your shipping provider expects them another way. Your email service has its own format.
And somewhere in between, variations multiply.
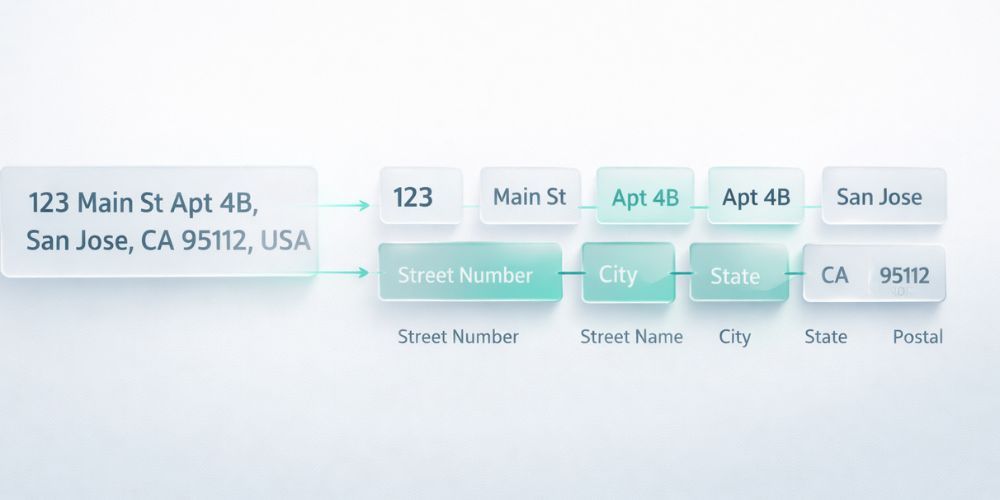
The Components: Street, Unit, City, State, Postal, Country
Every address contains up to six core components. Getting them right matters more than you might expect.
Street address includes the building number and street name. This is where most variation happens: "123 Main Street" versus "123 Main St" versus "123 Main St." All the same. All different in your database.
Unit or apartment number is optional but creates chaos when present. Is it "Apt 4B" or "#4B" or "Unit 4B" or just "4B"? Some systems put it on its own line, others append it to the street address, and a few creative souls stick it after the city.
City should be straightforward but isn't. "NYC" and "New York" and "New York City" are the same place. So are "LA" and "Los Angeles." Neighborhood names complicate things further. Is it "Brooklyn" or "New York"? Technically both are correct.
State or province has a standard abbreviation in most countries, but people use full names anyway. "California" becomes "CA" or "Calif" or stays "California" depending on who entered the data.
Postal code format varies by country. US ZIP codes might include the +4 extension (or not). Canadian postal codes have a space in the middle (or not). UK postcodes follow a completely different pattern.
Country is often omitted for domestic addresses, which creates problems the moment you go international. "United States" versus "US" versus "USA" versus "U.S.A." All valid. None equivalent in a string comparison.
Common Variations That Break Matching
Street type abbreviations are the most common standardization headache. The same street appears as:
- Street, St, St., ST, str
- Avenue, Ave, Ave., AV, Av
- Boulevard, Blvd, Blvd., BL
- Drive, Dr, Dr., DR
Directional prefixes and suffixes add another layer. "123 North Main Street" might be recorded as "123 N Main St" or "123 N. Main Street" or "123 Main Street North." These are potentially different actual locations, so standardization needs to preserve the directional information, not just strip it out.
Then there's capitalization. "main street" and "MAIN STREET" and "Main Street" should match, but a naive string comparison says they're different. Title case normalization seems obvious, but what about names like "McDonald" or "O'Brien"? Those have specific capitalization rules that break simple case transformations.
Punctuation inconsistency completes the mess. Periods after abbreviations. Commas between components. Hyphens in building numbers. Each optional. Each creating variation.
The Apartment and Suite Chaos
Secondary address units deserve their own section because they cause an outsized share of matching failures.
Consider a single apartment. Depending on who entered the data, it might appear as:
- 123 Main St Apt 4B
- 123 Main St, Apt. 4B
- 123 Main St #4B
- 123 Main St Unit 4B
- 123 Main St, 4B
- 123 Main St (4B)
Some systems store this in a separate field. Others concatenate it. A few split it across two fields with different labels ("Apt/Suite" versus "Unit #" versus "Secondary Address"). When you merge data from multiple sources, you're reconciling all these conventions into something coherent.
Business addresses add suite numbers, floor numbers, building names, and mail stop codes. "Suite 500" and "Ste 500" and "Fl 5" might all refer to the same office. Or they might not. Context matters, and context is exactly what gets lost in data transfers.
International Address Formats
Everything I've described so far assumes US-style addresses. International formats introduce entirely different structures.
In the UK, postcodes come at the end and follow a letter-number pattern. In Japan, addresses start with the prefecture and work down to the building, essentially reversed from Western conventions. Germany puts the postal code before the city. Many countries have multiple official languages, so the same city might have two or three valid names.
If you're running an e-commerce operation that ships internationally, your address standardization strategy needs to account for these variations. A one-size-fits-all normalization will mangle valid addresses in other countries.
The practical approach is country-specific rules. Detect the country first (from explicit country field, postal code format, or other signals), then apply the appropriate standardization logic. This is harder than it sounds, especially when country information is missing or ambiguous.
Verification vs. Standardization: What's the Difference?
These terms get used interchangeably, but they solve different problems.
Address standardization normalizes format. It converts "123 Main St" and "123 Main Street" to the same representation so they match in your database. It doesn't tell you whether that address actually exists or whether mail will get there.
Address verification checks validity. It confirms that 123 Main Street exists in the specified city and state. It might also append missing components (like the +4 ZIP extension) or correct minor typos. This typically requires an external database lookup, often via a paid API service.
For most data cleaning purposes, standardization is the first priority. You can't effectively deduplicate records if "123 Main St" and "123 Main Street" look like different addresses. Verification is valuable but secondary; it's an enhancement step that comes after your data is internally consistent.
The cost difference matters too. Standardization can run locally with rules and pattern matching. Verification requires per-lookup fees that add up quickly across large datasets.
When Good Enough Is Good Enough
Perfect address data is a fiction. At some point, you're chasing diminishing returns.
The question isn't whether your addresses are perfect. It's whether they're consistent enough to serve your actual business needs.
If you're using addresses for customer deduplication, you need matching addresses to look identical (or nearly identical) in your database. That's a standardization problem.
If you're using addresses for shipping, you need deliverable addresses. That might require verification for new entries, but batch cleanup of existing data can often rely on standardization plus basic validation rules.
If you're using addresses for analytics (mapping customer distribution, regional sales analysis), you need geocodable addresses. That's a different bar than deliverability.
Define your use case. Then standardize to that level. Resist the urge to solve every possible address problem when you only need to solve yours.
Handling Address Standardization at Scale
Manual address cleanup doesn't scale. When you're looking at thousands of records with inconsistent formatting, you need automated standardization that understands the nuances.
This is the exact problem we built CleanSmart to solve. AutoFormat handles the common variations automatically: normalizing street type abbreviations, fixing capitalization, standardizing punctuation. SmartMatch then identifies duplicate records that represent the same location, even when the address strings aren't identical.
The result is a dataset where "123 Main St Apt 4B" and "123 Main Street, Unit 4B" are recognized as the same address. Your customer records actually reflect your customer count. Your shipping data becomes reliable. Your analytics stop lying to you about geographic distribution.
Standardize addresses across your entire dataset with a single cleaning pass. That's what CleanSmart does.
What's the most common address standardization mistake?
Treating standardization as a one-time project rather than an ongoing process. Address data degrades over time as new records enter your system through different channels. Build standardization into your data intake workflow, not just your cleanup routine.
Should I standardize addresses before or after deduplication?
Before. Deduplication relies on matching similar records, and unstandardized addresses make that matching unreliable. Two records with the same person at "123 Main St" and "123 Main Street" won't match without standardization first. Clean the formatting, then find the duplicates.
Do I need to pay for address verification services?
It depends on your use case. For deduplication and internal consistency, standardization without external verification is usually sufficient. For shipping-critical applications where deliverability matters, verification services can catch invalid addresses that standardization alone won't flag. Start with standardization, then add verification where the cost is justified by the business need.
What's the most common address standardization mistake?
Treating standardization as a one-time project rather than an ongoing process. Address data degrades over time as new records enter your system through different channels. Build standardization into your data intake workflow, not just your cleanup routine.
Should I standardize addresses before or after deduplication?
Before. Deduplication relies on matching similar records, and unstandardized addresses make that matching unreliable. Two records with the same person at "123 Main St" and "123 Main Street" won't match without standardization first. Clean the formatting, then find the duplicates.
Do I need to pay for address verification services?
It depends on your use case. For deduplication and internal consistency, standardization without external verification is usually sufficient. For shipping-critical applications where deliverability matters, verification services can catch invalid addresses that standardization alone won't flag. Start with standardization, then add verification where the cost is justified by the business need.