Most RevOps functions look great on an org chart and fall apart in practice. The team gets stood up, a few dashboards go live, and then six months later sales still doesn't trust the pipeline numbers, marketing is reporting different revenue figures than finance, and the ops team spends most of its week fixing data instead of improving process.
If that sounds familiar, you're not doing it wrong. You're doing it the way almost everyone does it. RevOps is genuinely hard, and the gap between the idea and the execution is where most teams get stuck.
This guide skips the theory. These are the practices that separate RevOps functions that drive results from the ones that become an expensive reporting layer. Most of them come back to one thing, so we'll start there.

Why Most RevOps Initiatives Fail
The failure pattern is predictable. A company hits a growth stage where sales, marketing, and customer success are stepping on each other. Leadership decides the fix is RevOps. They hire a leader, maybe a few analysts, buy some tooling, and expect alignment to follow.
It doesn't, because the underlying problem was never the org structure. It was the data.
When your CRM is full of duplicate accounts, half-filled records, and contacts with formatting so inconsistent that automation breaks, no amount of process design saves you. Your forecasts are built on bad inputs. Your attribution is guesswork. Your routing rules misfire because the data they depend on is unreliable. The RevOps team ends up firefighting instead of building.
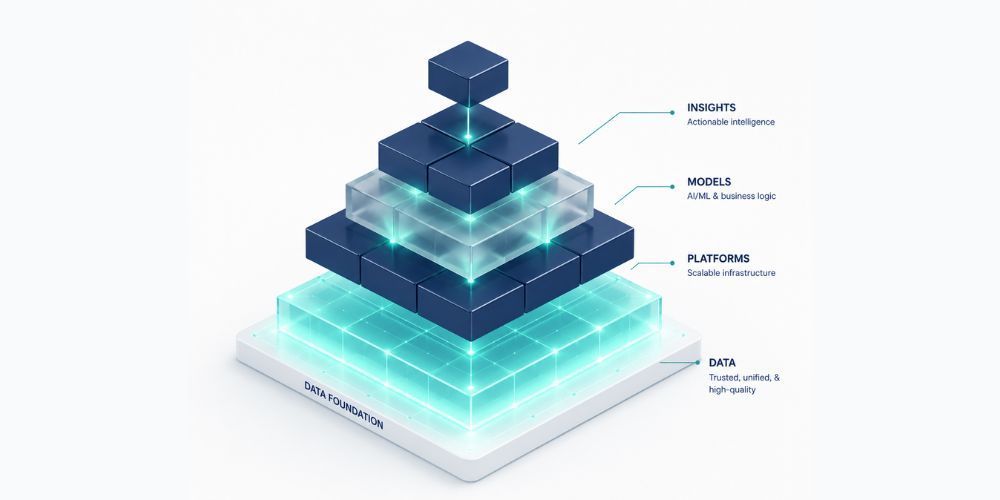
The teams that succeed treat data quality as the foundation, not a cleanup project they'll get to later. Everything else in this guide assumes you've accepted that premise.
Best Practice 1: Start With the Data Foundation
Before you redesign a single workflow, get honest about the state of your data. Pull a sample of records from your CRM and actually look at them. How many duplicates can you find in five minutes? How many records are missing critical fields? How many phone numbers and email addresses are formatted three different ways?
This audit is uncomfortable, which is exactly why most teams skip it. They'd rather build the new lead-scoring model than confront the fact that the data feeding it is a mess.
Don't skip it. The point isn't to fix everything at once. It's to understand what you're working with so you can prioritize. A quick assessment tells you whether you're dealing with a minor cleanup or a structural problem that needs ongoing attention.
When you do start resolving issues, semantic matching matters here. Traditional exact-match deduplication misses the records that cause the most damage. "Acme Inc" and "Acme Incorporated" are the same company, but a string match treats them as two accounts, and your sales team works the same deal twice. Catching those requires matching on meaning, not just characters.
This is the exact problem we built CleanSmart to solve. SmartMatch uses semantic similarity to find the duplicates that slip past everything else, and the rest of the cleaning happens in the same pass.
Best Practice 2: Define Your Single Source of Truth
Ask five people at a growing company where customer data lives and you'll get five answers. The CRM. The marketing platform. A finance spreadsheet. The product database. Someone's personal export from last quarter.
That's the silo problem, and it quietly undermines every RevOps initiative. When the same customer exists in four systems with four slightly different versions of the truth, you can't report accurately and you can't automate confidently.
Pick a system of record for each type of data and make it official. Your CRM might own account and contact data. Your billing system owns revenue. Your product database owns usage. The goal isn't to force everything into one tool. It's to decide, deliberately, which system wins when they disagree.
Then unify the rest around those decisions. When you pull data from multiple platforms into one clean view, you need clear rules for what happens when sources conflict. Does the most recent value win? The most complete record? The designated master? Answer that before you merge, not after.
Best Practice 3: Align on Metrics Before Tools
The instinct when standing up RevOps is to buy software. A new analytics platform, a forecasting tool, a fancy dashboard layer. Resist it until you've agreed on what you're actually measuring.
Here's what goes wrong without that agreement. Marketing defines a qualified lead one way, sales defines it another, and the handoff becomes a fight every week. Finance counts revenue on contract signing, sales counts it on close, and the two numbers never reconcile. You can buy the best tool on the market and it'll just give you a slicker version of the same disagreement.
Get the definitions nailed down first. What counts as a qualified opportunity. When a deal moves between stages. How you attribute revenue to a channel. Write them down somewhere everyone can see. These definitions are more important than any tool, because the tool just operationalizes whatever you've already agreed to.
Once the metrics are clear, the tooling decision gets easier, because you know exactly what the tool needs to do.
Best Practice 4: Build for Iteration, Not Perfection
A lot of RevOps teams stall because they're trying to design the perfect system before they ship anything. The perfect lead-routing logic. The perfect forecasting model. The perfect data schema that anticipates every future need.
Perfect is the enemy here. Markets shift, your go-to-market motion evolves, and the process you designed for this quarter won't fit next year. If you spend three months building something flawless, it's already outdated by the time it launches.
Ship something good enough, watch how it performs, and improve it. A routing rule that handles 80 percent of cases today beats a comprehensive system that ships in Q3. You'll learn more from a week of real usage than a month of planning.
This applies to data work too. You don't need spotless data across every field before you start getting value. Resolve the issues that block your highest-priority workflows first, then keep improving from there. Continuous beats comprehensive almost every time.
Best Practice 5: Automate the Right Things
Automation is where RevOps earns its keep, and also where it does the most damage when applied carelessly. The rule is simple. Automate the repetitive, high-confidence work. Keep humans in the loop for anything ambiguous.
The mistake teams make is automating everything, including decisions that need judgment. They set up a rule that auto-merges any record that looks like a duplicate, and then it merges two different people who happen to share a name. Now they've corrupted data instead of cleaning it, and nobody trusts the system anymore.
The better model routes work by confidence. When a change is obvious and safe, apply it automatically. When it's uncertain, flag it for a human to review before anything happens. This is the principle behind CleanSmart's approach: high-confidence changes get applied automatically, low-confidence ones go to a review queue where a person makes the call. You get the speed of automation without surrendering control over the decisions that matter.
Start by automating the work that's both frequent and low-risk. Format standardization, obvious duplicate merges, filling gaps where the prediction is highly confident. Save your team's attention for the edge cases.
Best Practice 6: Create Feedback Loops
RevOps doesn't work as a one-way street where ops dictates process to the revenue teams. The people closest to the work see problems first, and if you don't have a way to hear from them, you'll keep optimizing things that don't matter while real friction goes unaddressed.
Build deliberate channels for feedback. Regular check-ins with sales and marketing leads. A simple way for reps to flag when a process is slowing them down. A habit of asking why a workflow isn't being adopted instead of assuming the team is just resistant.
Pay attention to usage, not just opinions. If you roll out a new process and adoption is low, that's data. Either the process doesn't fit how people actually work, or you didn't bring them along. Both are fixable, but only if you're watching.
The same loop applies to data quality. When a rep tells you a record is wrong, that's not a complaint to manage. It's a signal about where your data is failing, and it's often the fastest way to find systemic issues.
Best Practice 7: Invest in Data Quality Continuously
Here's the practice that ties the whole function together, and the one teams most often treat as a one-time project. Data quality isn't something you fix once. It degrades constantly. Every new lead, every integration, every manual entry introduces fresh inconsistencies. A database you cleaned six months ago is dirty again today.
That's why the one-time cleanup approach fails. You spend a week getting the CRM into shape, declare victory, and within a quarter you're back where you started. The only thing that works is treating data hygiene as ongoing maintenance, like anything else that needs upkeep to stay reliable.
Build it into your rhythm. Run regular cleaning passes on your core systems. Standardize formatting as data comes in, not months later. Catch anomalies and impossible values before they pollute your reporting. Keep an audit trail so you can see what changed and trust the result.
This is genuinely tedious work, which is why automation belongs here more than anywhere. The right setup handles deduplication, formatting, gap-filling, and anomaly detection in a single pass, so maintaining quality doesn't consume your team's week. Clean data is RevOps best practice number one because every other practice in this guide depends on it. Get this right and the rest gets dramatically easier.
Common RevOps Mistakes to Avoid
A few patterns show up again and again. Worth naming them so you can spot them early.
Buying tools to solve process problems. A new platform won't fix misalignment. If sales and marketing don't agree on definitions, software just automates the confusion.
Treating data cleanup as a project, not a practice. Covered above, but it bears repeating because it's the most common and most expensive mistake. One-time cleanups don't hold.
Over-automating before the data is trustworthy. Automation amplifies whatever it's built on. Automate on bad data and you scale the mess faster.
Reporting in isolation. Dashboards nobody uses are a vanity exercise. If your metrics don't change how the revenue teams operate, they're decoration.
Trying to boil the ocean. Teams that attempt to fix everything at once usually finish nothing. Sequence the work and ship in pieces.
Ignoring adoption. A perfect process that reps route around is a failed process. Watch what people actually do, not what the playbook says they should.
Avoid these and you're already ahead of most RevOps functions, which spend their first year learning these lessons the expensive way.
Want to know where your own data foundation stands? Take the free RevOps Data Audit. Six questions, about two minutes, and you'll get a Clarity read on your data plus a prioritized fix list. No signup needed to see your score. Take the assessment ->
What is the most important RevOps best practice to start with?
Start with your data foundation. Before redesigning workflows or buying tools, audit the state of your CRM and core systems. Duplicates, missing fields, and inconsistent formatting undermine every other initiative, because forecasting, automation, and reporting all depend on clean inputs. Get an honest picture of your data quality first, then prioritize from there.
How long does it take to build a RevOps function that works?
There's no fixed timeline, but expect it to be ongoing rather than a project with an end date. You can stand up the basics and ship useful process in a quarter, but a RevOps function that actually drives results is built through continuous iteration. Aim for early wins on high-priority workflows, then keep improving. The teams that treat it as a one-time setup are the ones that struggle.
Do we need to fix all our data before implementing RevOps best practices?
No. Waiting for perfect data means never starting. Resolve the issues that block your highest-priority workflows first, then keep improving continuously. Data quality degrades over time regardless, so the goal isn't a one-time fix anyway. It's building maintenance into your regular rhythm so your data stays reliable as the business grows.
What is the most important RevOps best practice to start with?
Start with your data foundation. Before redesigning workflows or buying tools, audit the state of your CRM and core systems. Duplicates, missing fields, and inconsistent formatting undermine every other initiative, because forecasting, automation, and reporting all depend on clean inputs. Get an honest picture of your data quality first, then prioritize from there.
How long does it take to build a RevOps function that works?
There's no fixed timeline, but expect it to be ongoing rather than a project with an end date. You can stand up the basics and ship useful process in a quarter, but a RevOps function that actually drives results is built through continuous iteration. Aim for early wins on high-priority workflows, then keep improving. The teams that treat it as a one-time setup are the ones that struggle.
Do we need to fix all our data before implementing RevOps best practices?
No. Waiting for perfect data means never starting. Resolve the issues that block your highest-priority workflows first, then keep improving continuously. Data quality degrades over time regardless, so the goal isn't a one-time fix anyway. It's building maintenance into your regular rhythm so your data stays reliable as the business grows.