Here's a duplicate that most software will miss:
Record A: Jon Smyth, j.smyth@company.com, (555) 867-5309
Record B: Jonathan Smith, jonathan.smith@company.org, 555.867.5309
Same person. Different spelling. Different email domain. Different phone format. If you're running a marketing campaign and both records are in your list, Jonathan's getting two emails. Maybe two direct mail pieces. Definitely an impression that your company can't keep its data straight.
Traditional duplicate detection would look at these two records and shrug. Not a match.
And honestly? That's a problem.

The Three Tiers of Duplicate Detection
Most people think of deduplication as a simple yes-or-no question. Either two records match or they don't. But the reality is messier. There are actually three distinct approaches to finding duplicates, and each one catches a different slice of the problem.
Tier 1: Exact Matching
This is the baseline. Two records match if they're identical, character for character. "John Smith" equals "John Smith." Add a space, change a letter, flip the case—no match.
Exact matching is fast. It's simple. It catches the obvious stuff, like when someone submits a form twice in a row.
But it's also incredibly limited. Real-world data doesn't stay pristine. People misspell their own names. Systems import records with different formatting conventions. CRMs merge and split and accumulate cruft over years.
If you're only doing exact matching, you're catching maybe 10-15% of your actual duplicates.
Tier 2: Fuzzy Matching
Fuzzy matching was supposed to fix this. Instead of requiring perfect character-for-character alignment, fuzzy algorithms calculate how "similar" two strings are. The most common approach uses something called Levenshtein distance—basically counting how many single-character edits (insertions, deletions, substitutions) it takes to turn one string into another.
"John Smith" to "John Smyth" = 1 edit (i→y). High similarity. Probably a match.
"John Smith" to "Jon Smith" = 1 edit (delete h). High similarity. Probably a match.
This is better. Fuzzy matching catches typos, minor misspellings, and simple variations. Most duplicate detection software stops here, and for a while, it seemed like enough.
But then you run into "Jonathan Smith" vs "Jon Smyth."
The Levenshtein distance between those two names? Seven edits. That's a 65% similarity score at best. Most fuzzy matching systems would flag that as "not a match" and move on.
Except... they're obviously the same person. Jon is short for Jonathan. Smyth is an alternate spelling of Smith. Any human glancing at the full records would spot this in seconds.
Fuzzy matching doesn't understand meaning. It just counts characters.
Tier 3: Semantic Matching
This is where things get interesting.
Semantic matching doesn't compare characters. It compares meaning. Instead of asking "how many letters are different," it asks "do these two records refer to the same real-world entity?"
The technology behind this has changed dramatically in the past few years. Modern semantic matching uses transformer models—the same underlying architecture that powers large language models—to convert text into numerical representations called embeddings. These embeddings capture the meaning of words and phrases, not just their spelling.
When a semantic model looks at "Jonathan" and "Jon," it recognizes them as variations of the same name. When it sees "Smith" and "Smyth," it understands they're phonetically identical and commonly interchanged. When it compares full records, it weighs all the evidence: the names are related, the phone numbers match (once you normalize the format), the email usernames are similar.
The result? A high-confidence match that fuzzy logic completely missed.
Where Each Method Breaks Down
Let me show you some real examples. I've seen all of these in actual customer data.
Example 1: The Nickname Problem
- Record A: "William Chen"
- Record B: "Bill Chen"
Fuzzy similarity: ~70%. Most systems would call this "uncertain" or "review manually."
Semantic analysis: Recognizes William/Bill as the same name. High-confidence match.
Example 2: The Maiden Name Problem
- Record A: "Sarah Johnson, sarah.j@email.com"
- Record B: "Sarah Miller, sarah.j@email.com"
Fuzzy matching on names alone: Low similarity. Not a match.
Semantic matching: Same email address, same first name. Flags as likely duplicate with name change. (This happens constantly in B2C databases.)
Example 3: The International Formatting Problem
- Record A: "François Müller, +33 6 12 34 56 78"
- Record B: "Francois Mueller, 0033612345678"
Fuzzy matching: The accented characters alone tank the similarity score.
Semantic matching: Normalizes accents and diacritics, recognizes the phone numbers as identical. Match.
Example 4: The Data Entry Chaos Problem
- Record A: "Dr. Robert James Thompson III, MD"
- Record B: "Bob Thompson"
Fuzzy matching: Where do you even start? These strings are completely different lengths.
Semantic matching: Extracts the core name components, recognizes Robert/Bob, weighs against other fields. If the address or phone matches, it's flagged for review.
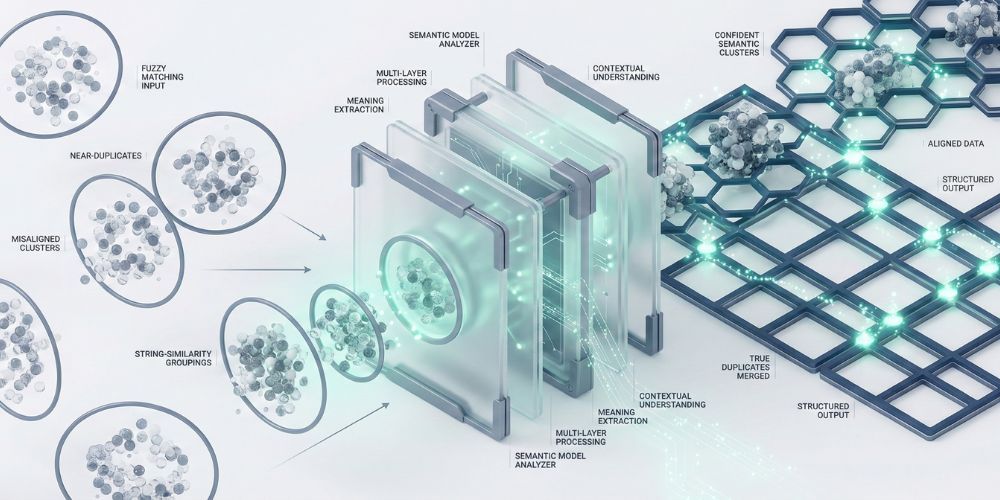
How Semantic Matching Actually Works (Without the PhD)
I'll spare you the linear algebra. Here's the practical version.
When you feed a record into a semantic matching system, it doesn't see "Jonathan Smith" as seven individual letters. It converts the entire name—and ideally the whole record—into a point in high-dimensional space. Similar meanings end up close together in that space, even if the spelling is completely different.
Think of it like this: if you plotted every possible name on a map, "Jon," "Jonathan," "Jonny," and "John" would all be clustered in the same neighborhood. "Smyth," "Smith," and "Smithe" would be neighbors too. When the system compares two records, it's measuring the distance between their positions on this map.
The transformer models that power this have been trained on massive amounts of text. They've seen millions of examples of name variations, nicknames, and common misspellings. They've learned that "Bob" and "Robert" refer to the same person, even though they share only one letter.
This isn't magic. It's pattern recognition at a scale humans can't match manually.
A Real Before-and-After
One of our beta users uploaded a CRM export with 12,000 contact records. They'd been doing annual "cleanup" using their CRM's built-in deduplication, which relied on exact and fuzzy matching.
Results from their existing tool: 847 duplicate pairs found.
Results from SmartMatch™: 2,341 duplicate pairs found—including 1,494 that fuzzy matching missed entirely.
That's a 176% increase in duplicate detection. Nearly three times the cleanup. And when they reviewed a sample of the "new" matches, the accuracy rate was above 94%.
The kicker? Their marketing team had been complaining for months about customers receiving multiple emails. They'd assumed it was a segmentation problem. It was a duplicate problem that their existing tools couldn't see.
The Catch (Because There's Always a Catch)
Semantic matching isn't perfect. Nothing is.
It requires more computational resources than simple fuzzy matching. Processing takes longer. And because it's finding more potential matches, it can generate more false positives if not tuned properly.
That's why we built SmartMatch™ with human review workflows. The AI does the heavy lifting—surfacing matches that would take humans weeks to find manually—but you stay in control of what actually gets merged.
We also combine approaches. SmartMatch uses exact matching as a first pass (it's fast and catches the obvious stuff), then fuzzy matching for near-misses, then semantic analysis for the hard cases. Each layer builds on the last.
The Bottom Line
If you're still relying on exact matching or basic fuzzy logic for deduplication, you're missing the majority of your duplicates. Not because the tools are broken—they're doing exactly what they were designed to do. They're just designed for a simpler problem than the one you actually have.
Semantic matching isn't a luxury anymore. It's the difference between "we cleaned up some duplicates" and "we actually trust this data."
Ready to see what you're missing? Upload a dataset to CleanSmart and let SmartMatch™ show you the duplicates hiding in plain sight. Free trial, no credit card required.
How is semantic matching different from the "fuzzy deduplication" in my CRM?
Most CRM deduplication tools use string similarity algorithms—they compare characters, not meaning. If two names are spelled differently enough, those tools miss the match. Semantic matching uses AI models trained to understand that "Bob" and "Robert" are the same name, "Smyth" and "Smith" are variants, and "Jon" is short for "Jonathan." It's comparing what records mean, not just what they look like.
Will semantic matching create more false positives?
It can surface more potential matches, yes—that's the point. But CleanSmart shows you confidence scores for every match and lets you review suggestions before anything merges. You're not blindly trusting the AI. You're using it to find candidates that would've taken hours to discover manually, then making the final call yourself.
How long does semantic matching take compared to fuzzy matching?
Longer, but not as much as you'd think. For a typical 10,000-record file, standard fuzzy matching might take 30-60 seconds. SmartMatch™ typically completes in 2-4 minutes because it's running multiple analysis passes. The tradeoff is catching 2-3x more duplicates. For most teams, an extra minute or two of processing time is worth finding hundreds of duplicates they'd otherwise miss.
How is semantic matching different from the "fuzzy deduplication" in my CRM?
Most CRM deduplication tools use string similarity algorithms—they compare characters, not meaning. If two names are spelled differently enough, those tools miss the match. Semantic matching uses AI models trained to understand that "Bob" and "Robert" are the same name, "Smyth" and "Smith" are variants, and "Jon" is short for "Jonathan." It's comparing what records mean, not just what they look like.
Will semantic matching create more false positives?
It can surface more potential matches, yes—that's the point. But CleanSmart shows you confidence scores for every match and lets you review suggestions before anything merges. You're not blindly trusting the AI. You're using it to find candidates that would've taken hours to discover manually, then making the final call yourself.
How long does semantic matching take compared to fuzzy matching?
Longer, but not as much as you'd think. For a typical 10,000-record file, standard fuzzy matching might take 30-60 seconds. SmartMatch™ typically completes in 2-4 minutes because it's running multiple analysis passes. The tradeoff is catching 2-3x more duplicates. For most teams, an extra minute or two of processing time is worth finding hundreds of duplicates they'd otherwise miss.